


Next: Incorporating language restrictions
Up: Crash course in optical
Previous: Probabilistic description
If one assumes that all letters occur independently of one another
and with the same probability, then the letter co-occurrence
probability 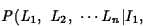 is the same for all
word hypotheses, and so that term effectively drops out of
the maximization problem for Eq.
is the same for all
word hypotheses, and so that term effectively drops out of
the maximization problem for Eq. ![[*]](/Graphics/LaTeX/icons.gif/cross_ref_motif.gif) .
The expression to be maximized is now just the image
generation probability:
.
The expression to be maximized is now just the image
generation probability:
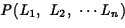
We will assume for simplicity
that knowledge of the identity of a letter completely determines
the probability that a given image will be generated for that letter,
and that the images for different letters within a given word are
generated independently of one another;
image probabilities for various letters have to be learned by
the system by examining multiple sample images for each letter.
The above expression then simplifies:
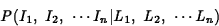
It is now possible to break the maximization problem down into n
subproblems: for each position in the sequence, one selects the letter
that is most consistent with the image for that position; in other words,
Lk should maximize the expression P(Ik | Lk). The resulting
sequence of letters is then the ``winning'' word.
Models such as those described above use knowledge about image generation,
and in particular about the consistency between a given image and the
hypothesis that a particular letter may have given rise to that image.
However, such models completely ignore the letter-order restrictions
that exist in English; for instance, the sequence ``cmt'' could beat
``cat'', despite one's intuitive sense that there should be a strong
syntactical preference in favor of the latter.
Next: Incorporating language restrictions
Up: Crash course in optical
Previous: Probabilistic description
Sergio A. Alvarez
4/26/2000